Bonjour,
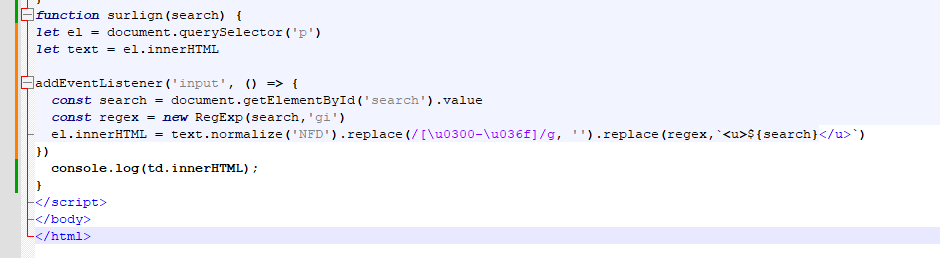
J'ai par exemple dans une balise <p> un texte avec ou sans majuscule.
Je souhaite remplacer tous les "dog" qu'ils soit en majuscule ou pas par <u>dog</u> en respectant la casse d'origine. Et donc en sortie aussi.
Au final cela donnerait :
J'ai bien essayer le classique replaceAll, ensuite j'ai essayé avec indexof et slice.
Mais je n'y arrive pas.
En javascript (pas en jquery)
Auriez-vous une solution ?
Cordialement Jérôme
J'ai par exemple dans une balise <p> un texte avec ou sans majuscule.
<html>
<body>
<p>I think Ruth's dog is cuter DOG than your dog! to Dog to dog</p>
</body>
</html>Je souhaite remplacer tous les "dog" qu'ils soit en majuscule ou pas par <u>dog</u> en respectant la casse d'origine. Et donc en sortie aussi.
Au final cela donnerait :
<p>I think Ruth's <u>dog</u> is cuter <u>DOG</u> than your <u>dog</u>! to <u>Dog</u> to <u>dog</u></p>J'ai bien essayer le classique replaceAll, ensuite j'ai essayé avec indexof et slice.
Mais je n'y arrive pas.
En javascript (pas en jquery)
Auriez-vous une solution ?
Cordialement Jérôme



 (si j'éclate sur les ,!' je ne sais pas la reconstruire ensuite, si je match w+|W+ il m’éclate certains mots comme si dög était trois mots..
(si j'éclate sur les ,!' je ne sais pas la reconstruire ensuite, si je match w+|W+ il m’éclate certains mots comme si dög était trois mots..