(reprise du message précédent)
Est-ce que :
correspond du coup ?

https://regexr.com/5mp6s
(oops j'ai oublié les caractères spéciaux comme le î )
)
(et mince j'ai perdu les - aussi... )
)
Modifié par _laurent (18 Feb 2021 - 15:02)
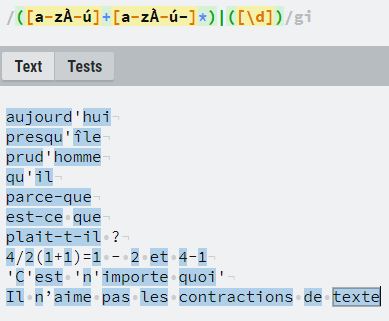
Est-ce que :
[^\d\W]+[^\d\W-]*|[\d]*correspond du coup ?
https://regexr.com/5mp6s
(oops j'ai oublié les caractères spéciaux comme le î
) (et mince j'ai perdu les - aussi...
) Modifié par _laurent (18 Feb 2021 - 15:02)