Bonjour,
D'après certaines personnes, les espaces autres que ne sont pas tous compris par tous les navigateurs.
J'ai vu cette astuce toute simple sur un site belge traitant de typo et d'espaces en tous genres ; elle me semble bonne à connaître pour ceux qui veulent une espace insécable entre le texte et les signes de ponctuation doubles comme les guillemets à la française, canadienne ou belge (en suisse francophone : pas d'espace). Mais qui veulent cette espace plus petite que la taille normale car il est vrai qu'elle est un peu disgracieuse.
Puis dans votre html :
<p>Visitez le site «<span class='nbthinsp'> </span>Alsacréations<span class='nbthinsp'> </span>» vous ne le regreterez pas<span class='nbthinsp'> </span>!</p>
Ce qui nous donne quelque chose de plus esthétique :
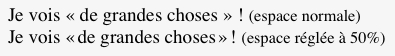
Ben oui, c'est un peu long à coder mais, avec un petit zeste de PHP on fait ça en trois coups de cuiller à pot :
Avec bien sûr quelque part dans votre page :
PS : J'espère que ce petit truc n'a pas déjà été posté sur Alsacréations. (la recherche n'a rien donné)
Modifié par Aureance (24 Feb 2010 - 14:37)
D'après certaines personnes, les espaces autres que ne sont pas tous compris par tous les navigateurs.
J'ai vu cette astuce toute simple sur un site belge traitant de typo et d'espaces en tous genres ; elle me semble bonne à connaître pour ceux qui veulent une espace insécable entre le texte et les signes de ponctuation doubles comme les guillemets à la française, canadienne ou belge (en suisse francophone : pas d'espace). Mais qui veulent cette espace plus petite que la taille normale car il est vrai qu'elle est un peu disgracieuse.
/* pour une classe NoBreakingThinSpace par exemple */
.nbthinsp { font-size: 50%; }
/* Utilisez la même unité que pour votre texte . Si votre texte est en em : font-size en em */Puis dans votre html :
<p>Visitez le site «<span class='nbthinsp'> </span>Alsacréations<span class='nbthinsp'> </span>» vous ne le regreterez pas<span class='nbthinsp'> </span>!</p>
Ce qui nous donne quelque chose de plus esthétique :
Ben oui, c'est un peu long à coder mais, avec un petit zeste de PHP on fait ça en trois coups de cuiller à pot :
function nbthinsp($texte) {
$sp = '<span class="nbthinsp"> </span>';
$rechercher = array('« ', ' »', ' !', ' ?', ' ;', ' :');
$remplacer = array('«'.$sp, $sp.'»', $sp.'!', $sp.'?', $sp.';', $sp.':');
$correction = str_replace($rechercher, $remplacer, $texte);
return $correction;
}Avec bien sûr quelque part dans votre page :
<?php echo nbthinsp($le_texte_a_traiter);?>PS : J'espère que ce petit truc n'a pas déjà été posté sur Alsacréations. (la recherche n'a rien donné)
Modifié par Aureance (24 Feb 2010 - 14:37)




