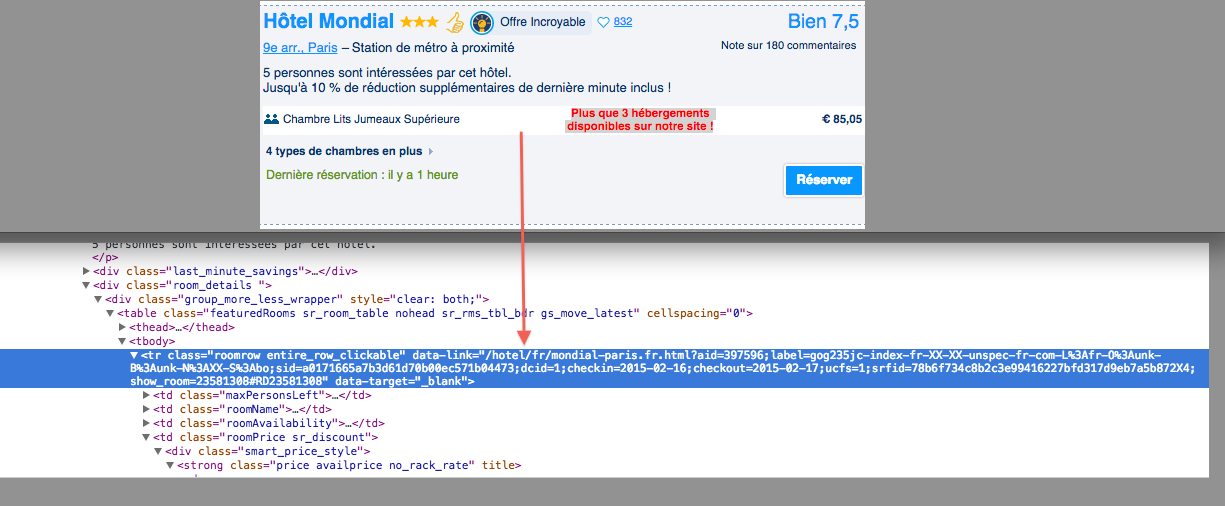
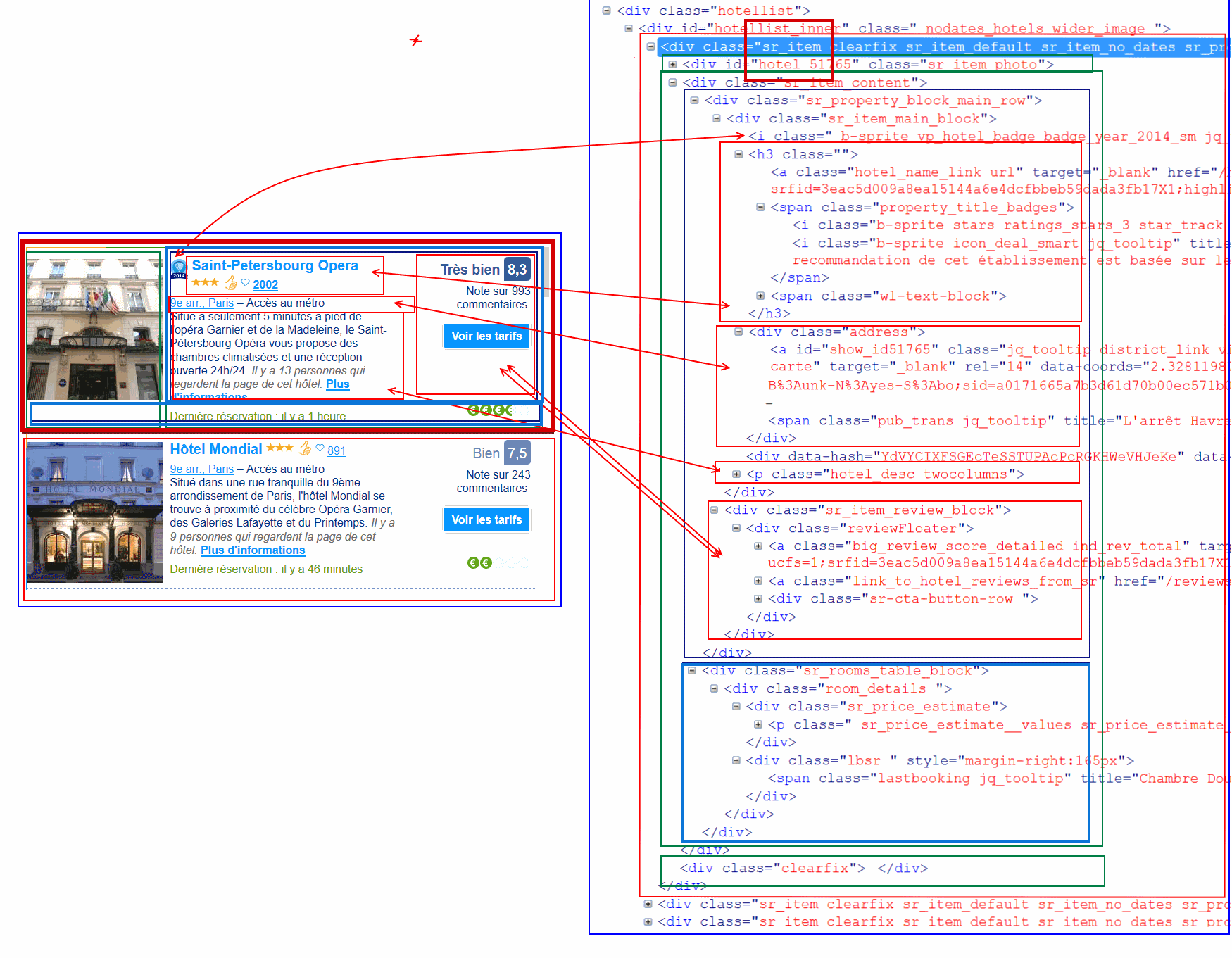
Le post est un peu vieux mais bon ........pour utiliser xpath , il faut étudier pour chaque page toutes les options visible ( texte image) ou invisible ( valeurs des id class) et parser en fonction de chaque cas . Le premier item est détecté par la valeur de class ".sr_item" ( csspar ser) .. Si le contenu change selon les pages il faut tester le retour de la valeur de xpath avant d'extraire la valeur . ici la page montre 15 valeurs count(/html/*/*/*/*/*/*/*/*/*/*/div[contains(@class, 'sr_item')]) a parser . pour chaque item on extrait les sous items. regexp peut être mixer avec xpath si le contenu contient des items identiques .
A première vues sans voir le xpath je me demande si celui ci n 'aurait pas des sélecteurs trop spécifique concernant le prix a extraire . il faut tester l expression xpath en manuel sur plusieurs pages .
Il faut que l environnement qui parse soit reconnu comme ayant les fonctionnalités qu'un navigateur web (support http , gestion des cookies , javascript )
Ai déja fait ça en python avec
http://4suite.org/ et regexp avec requête dynamique et sauvegarde dans une table mysql . Beaucoups de travail mais maintenant un mix selenium et javascript devrait faire cela ( il doit y avoir un debut de post sur alsa chercher RSS jsonp ) .
NB
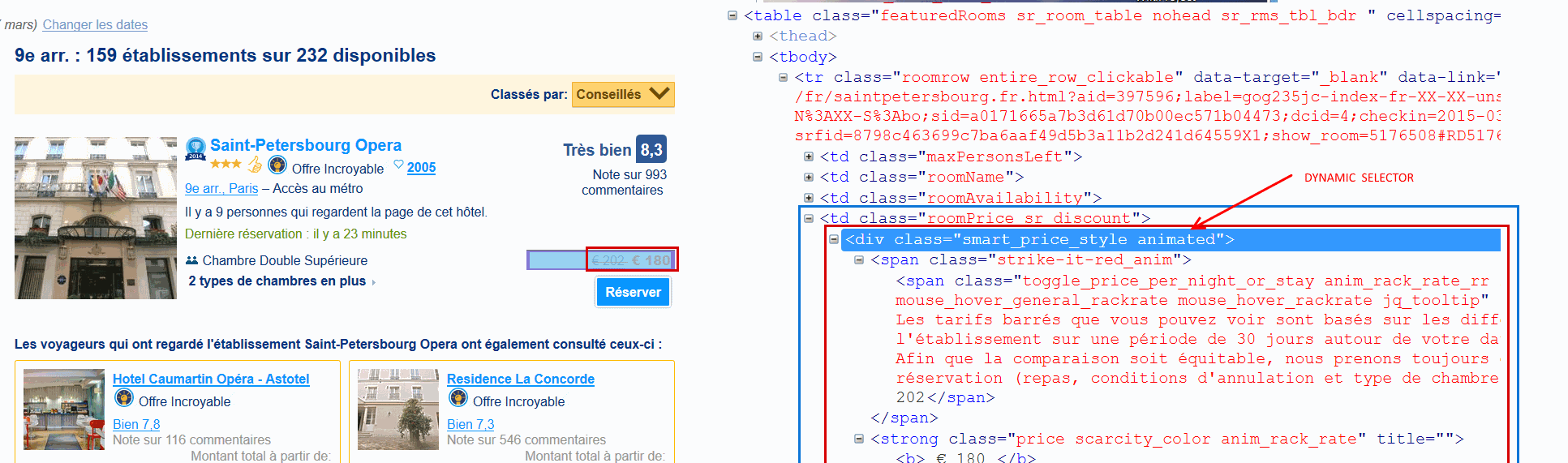
nb pour empécher de parser les données , les sites ne montrent certaines informations qu'après un click de souris sur une zone spécifique (ici le prix !!) après c 'est le jeux du chat et de la souris . En effet , le webmaster du sites consulte le fichier de log du serveur pour identifier des requêtes étrange ( strange user agent name ) . Les données valant de l'or.... peu de sites laisseraient un robot extraire leurs données. Ils amélioraient leur système en utilisant technique http,html/css et javascript ou autres astuces comme modifier la structure des données . Ici booking.com utilise span pour simuler un boutton et le click entraine une requête sur le server pour afficher une nouvelle page qui elle afiche le prix .Le prix s affiche [que si l on clique sur l item prix ( 1ere page ) ] dans la deuxième page . Dans cette 2eme page le prix "apparait" dans une table ( <table>) contenant des champs vide ou se trouveront les données ajouté par javascript .En effet le prix ne s affiche que si la partie prix ( graphique) est visible sur la page . Une fois visible ; si le prix disparait du au scroll de la souris alors le prix reste visible dans le code source . Le script aurait pu inverser les choses et le faire disparaitre à nouveau le prix en dehors de la zone de visibilité du navigateur ( mix selecteur dynamique et css) . Il semble que l apparition n'es tqu un effet visuel car la valeur recherché est dans le code source html au bon emplacement.L'information aurait pu être absente et ajouté dynamiquement par code javascript lors du scroll . Sur cette page on retrouve bien la table de votre capture . Sur le prix qui s affiche il y a aussi un menu associé . Le prix se trouve dans <span class="strike-it-red_anim">
<span id="b_tt_holder_2" class="toggle_price_per_night_or_stay anim_rack_rate_rr read-easy rackrate mouse_hover_general_rackrate mouse_hover_rackrate jq_tooltip" style="cursor:help;" "="" rel="400" data-toponly="1" data-title=" texte">€ 185</span>
".rackrate" en css est le prix barré
".anim_rack_rate" en css est le prix que vous recherché
un fichier css dynamique contient .anim_rack_rate b { visibility: hidden;} qui
visible par .animated .anim_rack_rate b { visibility: visible;} . Il y a donc ajout d un selecteur de nom animated ( voir capture) . Il me semble que le prix est déja présent dans le code html mais que le code html est généré dynamiquement coté client . certains code javascript utlisent des variables a 1/2 caractères ( obfuscator ?)
sinon l info du prix ( plusieurs items ) semble se trouver dans le code source javascript au niveau de
<script id="booking-script-maps-google" type="text/javascript"> booking.loadCurrentHotels = function() { }
chaque item vaut
hotels.push({ "gc": false,
"b_id" : 51765,
"b_main_photo" : 'http://q-ec.bstatic.com/images/hotel/square60/561/561477.jpg',
"b_description" : "Situé à seulement 5 minutes à pied de l\'opéra Garnier et de la Madeleine, le Saint-Pétersbourg Opéra vous propose des chambres climatisées et une réception ouverte 24h/24. ",
"b_name" : "Saint-Petersbourg Opera",
"b_latitude" : 48.87215141747105,
"b_longitude" : 2.3281198740005493,
"b_class" : 3,
"b_class_is_estimated": "0",
"b_url" : "/hotel/fr/saintpetersbourg.fr.html?aid=397596;label=gog235jc-index-fr-XX- XX-unspec-fr-com-L%3Afr-O%3Aunk-B%3Aunk-N%3AXX-S%3Abo;
sid=a0171665a7b3d61d70b00ec571b04473;
dcid=4;
checkin=2015-03-16;checkout=2015-03-17;ucfs=1;
srfid=8798c463699c7ba6aaf49d5b3a11b2d241d64559X1" ,
"prices" : [ { "room_price" : "€ 180", "room_persons" : "2" } , { "room_price" : "€ 189", "room_persons" : "2" } , { "room_price" : "€ 231", "room_persons" : "3" } , { "room_price" : "€ 245", "room_persons" : "2" } , { "room_price" : "€ 258", "room_persons" : "2" } ] ,
"b_has_genius_rates" : !!(parseInt('0',10)) });
nombre chargé / visible est .sr_item/ .animated. mais lesv aleurs semble présetne dans larbre html mais seulement pas visible.
NB changer regulièrement
a) d IP ( vpn ?)
b) de http-header ( mappping proxy ?
sinon j ai utiliser la syntaxe de selection css dans mes réponses a convertir en expression de sélection xpath si vous allez dans cette voie ......
Voila un début d 'idée ... rien n'est facile ....mais on apprend beaucoups .....
Modifié par 75lionel (07 Mar 2015 - 10:21)