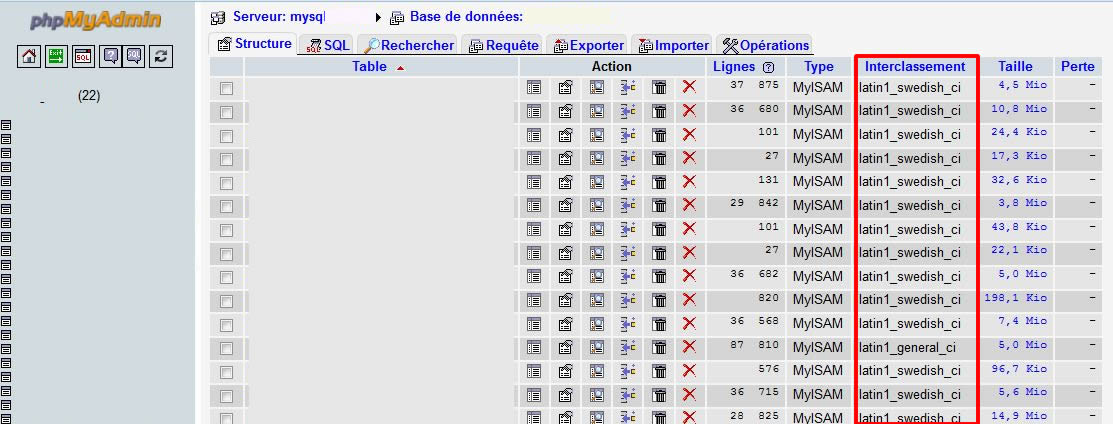
Bonjour,
J'ai un site internet valid (W3C) XHTML 1.0 Strict!
Lorsque je passe en htlm5
<!doctype html>
<html lang="fr">
<head>
<meta charset="iso-8859-1">
<title>Mon titre</title>
J'obtiens 1 warning !
Using windows-1252 instead of the declared encoding iso-8859-1.
Étant absolument certain de ne pas avoir déclaré de : windows-1252 je me demande pourquoi.
En poursuivant mes recherches j'ai constaté dans Notepad++ que mes pages semblent être encodées en ANSI !!!
Est ce que j’obtiens ce warning à cause de ça ?
Ma petite question
Si je convertis toutes mes pages en UTF-8 quel genre de changement je risque d'avoir dans mes codes html et php ?
merci d'avance pour votre aide
J'ai un site internet valid (W3C) XHTML 1.0 Strict!
Lorsque je passe en htlm5
<!doctype html>
<html lang="fr">
<head>
<meta charset="iso-8859-1">
<title>Mon titre</title>
J'obtiens 1 warning !
Using windows-1252 instead of the declared encoding iso-8859-1.
Étant absolument certain de ne pas avoir déclaré de : windows-1252 je me demande pourquoi.
En poursuivant mes recherches j'ai constaté dans Notepad++ que mes pages semblent être encodées en ANSI !!!
Est ce que j’obtiens ce warning à cause de ça ?
Ma petite question
Si je convertis toutes mes pages en UTF-8 quel genre de changement je risque d'avoir dans mes codes html et php ?
merci d'avance pour votre aide


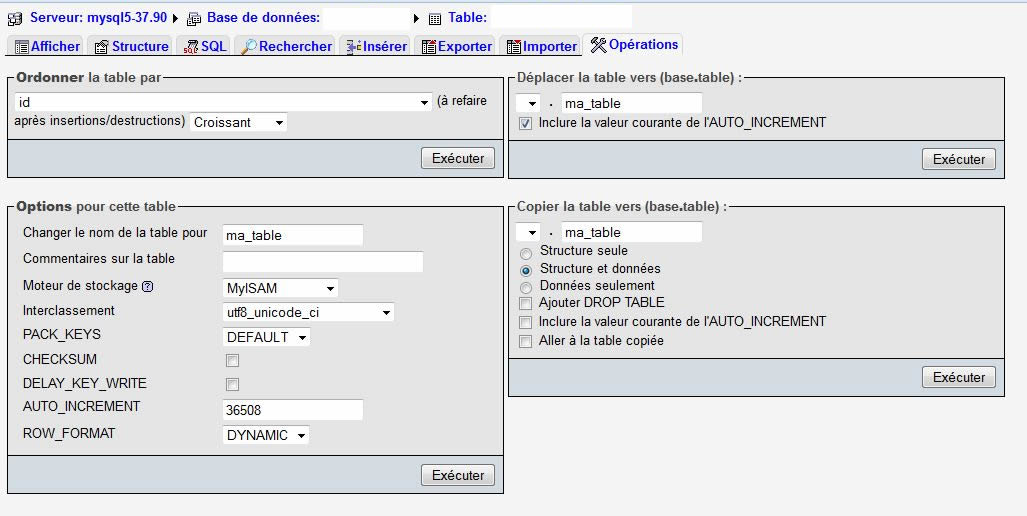

 ).
).