Bonjour,
Je suis intégrateur HTML depuis un certains temps, et là suis assez stupéfais d'une découverte. Si le problème a déjà été évoqué, j'en suis désolé, mais je n'ai rien trouvé.
Voilà le phénomène (auquel j'ai été confronté plusieurs fois) que j'aimerais maintenant comprendre :
Je fais un site à partir d'un template php déclaré en utf-8 dans le meta. Jusque là pas de problème et rien d'exceptionnel. Sauf qu'à l'affichage des caractères spéciaux (accents etc.) => problème d'affichage. Evidemment, tous les tutos du net réfèrenet ce genre de problèmes aux différentes déclarations d'encodage dans les <meta _______ />.
Sauf que dans mon cas, rien à voir.
Pour "corriger" le problème, j'ai du avoir recour à une manipulation laborieuse mais efficace (exemple avec un fichier "index.php"):
Le fichier index.php affiche mal les caractères spéciaux. Donc sous DW, je crée un nouveau document dans lequel je copie tout le code de mon index.php. Ensuite je crée un 3eme document en utf-8 sous DW, je sélectionne tout le code (pour avoir l'entete etc.) et je le colle dans mon index.php. Ctrl+s pour sauvegarder et ctrl+w pour quitté. Et la, chose étrange, alors que je viens juste de sauvegarder, il me redemande si je veux sauvegarder mon document avant de quitter. Je répond "oui". Ensuite je réouvre mon document, et je recolle tout le code que j'avais stocké dans mon fichier temporaire. Je sauvegarde, et là c'est bon.
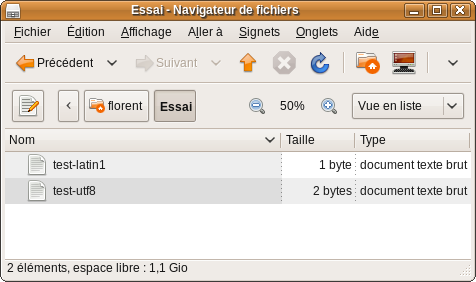
Conclusion : il est possible de se trouver avec 2 fichiers php (et même html j'imagine) totalement identique dans leur contenu, mais qui n'ont pas le même encodage. De plus, j'ai remarqué qu'outre leur aspect identique, les 2 fichiers n'avaient pas tout à fait le même poids, ce qui confirme bien que des métadonnées (ou sont-elles stockée ?)ont le dernier mot en ce qui concerne l'encodage.
Question : existe-il un logiciel, un éditeur etc. capable de traiter par lot ces fichiers afin de les convertir en masse à l'encodage souhaité ?
Je suis intégrateur HTML depuis un certains temps, et là suis assez stupéfais d'une découverte. Si le problème a déjà été évoqué, j'en suis désolé, mais je n'ai rien trouvé.
Voilà le phénomène (auquel j'ai été confronté plusieurs fois) que j'aimerais maintenant comprendre :
Je fais un site à partir d'un template php déclaré en utf-8 dans le meta. Jusque là pas de problème et rien d'exceptionnel. Sauf qu'à l'affichage des caractères spéciaux (accents etc.) => problème d'affichage. Evidemment, tous les tutos du net réfèrenet ce genre de problèmes aux différentes déclarations d'encodage dans les <meta _______ />.
Sauf que dans mon cas, rien à voir.
Pour "corriger" le problème, j'ai du avoir recour à une manipulation laborieuse mais efficace (exemple avec un fichier "index.php"):
Le fichier index.php affiche mal les caractères spéciaux. Donc sous DW, je crée un nouveau document dans lequel je copie tout le code de mon index.php. Ensuite je crée un 3eme document en utf-8 sous DW, je sélectionne tout le code (pour avoir l'entete etc.) et je le colle dans mon index.php. Ctrl+s pour sauvegarder et ctrl+w pour quitté. Et la, chose étrange, alors que je viens juste de sauvegarder, il me redemande si je veux sauvegarder mon document avant de quitter. Je répond "oui". Ensuite je réouvre mon document, et je recolle tout le code que j'avais stocké dans mon fichier temporaire. Je sauvegarde, et là c'est bon.
Conclusion : il est possible de se trouver avec 2 fichiers php (et même html j'imagine) totalement identique dans leur contenu, mais qui n'ont pas le même encodage. De plus, j'ai remarqué qu'outre leur aspect identique, les 2 fichiers n'avaient pas tout à fait le même poids, ce qui confirme bien que des métadonnées (ou sont-elles stockée ?)ont le dernier mot en ce qui concerne l'encodage.
Question : existe-il un logiciel, un éditeur etc. capable de traiter par lot ces fichiers afin de les convertir en masse à l'encodage souhaité ?