Bonjour tout le monde,
J'ai un petit souci de conception. Voici le code :
insertion en base :
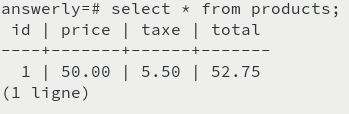
Lorsque je fais un select * from products, la colonne total est vide.
J'ai testé séparément la requete dans la fonction et j'obtiens un résultat probant:
Aussi, je n'ai pas de message erreur.
Savez vous d'où ça pourrait provenir ? Merci de vos lumières.
Bonne soirée à vous
Modifié par niuxe (15 Aug 2024 - 19:36)
J'ai un petit souci de conception. Voici le code :
CREATE OR REPLACE FUNCTION fetch_taxes_mount(price NUMERIC(5, 2), taxe_id INTEGER)
RETURNS NUMERIC(5, 2) LANGUAGE PLPGSQL AS $$
DECLARE total NUMERIC(5,2);
BEGIN
SELECT
(p.price + (p.price * t.mount / 100)) INTO total
FROM
products AS p
INNER JOIN
taxes AS t
ON
p.taxe_id = t.id
WHERE
p.taxe_id = $2;
RETURN total;
END;
$$ IMMUTABLE;
CREATE TABLE IF NOT EXISTS taxes(
id SERIAL PRIMARY KEY,
name VARCHAR(16),
mount NUMERIC(4,2)
);
CREATE TABLE IF NOT EXISTS products(
id SERIAL PRIMARY KEY,
price NUMERIC(5,2),
taxe_id INTEGER,
total NUMERIC(5,2) GENERATED ALWAYS AS ( fetch_taxes_mount(products.price, products.taxe_id) ) STORED,
CONSTRAINT products_taxes_id FOREIGN KEY(taxe_id) REFERENCES taxes(id) ON DELETE CASCADE ON UPDATE CASCADE
);
insertion en base :
INSERT INTO taxes(name, mount) VALUES('TVA_5', 5.50);
INSERT INTO taxes(name, mount) VALUES('TVA_20', 20.00);
INSERT INTO products(price, taxe_id) VALUES(
50,
2
);
Lorsque je fais un select * from products, la colonne total est vide.
J'ai testé séparément la requete dans la fonction et j'obtiens un résultat probant:
SELECT
(p.price + (p.price * t.mount / 100)) AS total
FROM
products AS p
INNER JOIN
taxes AS t
ON
p.taxe_id = t.id
WHERE
p.taxe_id = 2;
Aussi, je n'ai pas de message erreur.
Savez vous d'où ça pourrait provenir ? Merci de vos lumières.
Bonne soirée à vous
Modifié par niuxe (15 Aug 2024 - 19:36)