8826 sujets

rihab a écrit :
Merci niuxe je m'excuse je mal poser ma question je veux dire champs pas enregistrement
Donc si je manipule un table de 30 champs y a-t -il des soucis ?
Merci et je m'excuse encore
Ma réponse est la même : tant que tes données et ta structure sont intègres, il n'y a pas de soucis.
Cependant, 30 champs me paraissent curieux. Peux tu faire un dump de ta structure et l'éditer sur le forum afin qu'on puisse voir cela ?
Je pense que tes données ne sont pas du tout intègres. Je t'invite à parcourir cet article : forme normalisée sql
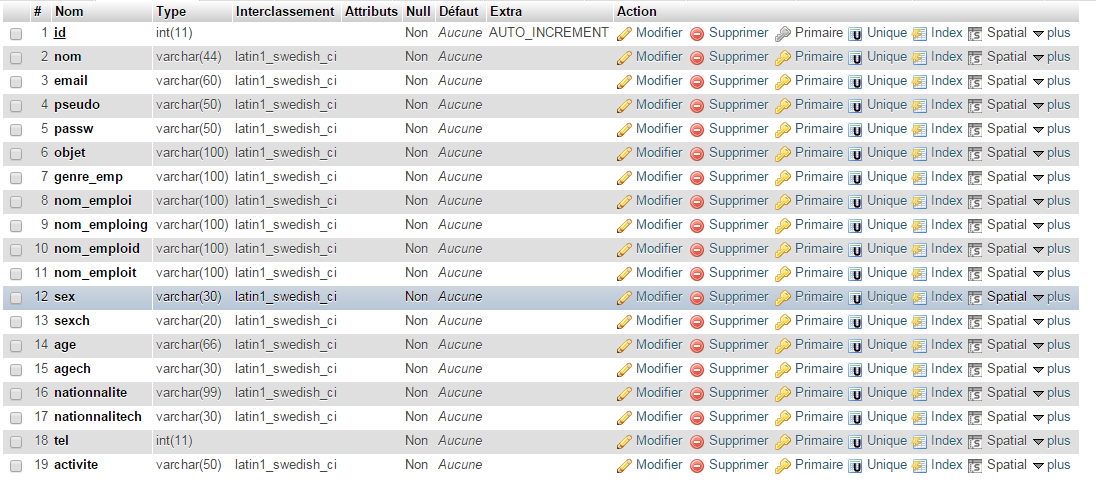
Peux tu me dire ce qu'est ce groupe de champ :
- genre_emploi
- nom_emploi
- nom_emploid
- nom_emploing
- nom_emploit
ou cet autre groupe :
- sex
- sexch
ou celui là encore :
- nationalité
- nationalitech
Peux tu me dire ce qu'est ce groupe de champ :
- genre_emploi
- nom_emploi
- nom_emploid
- nom_emploing
- nom_emploit
ou cet autre groupe :
- sex
- sexch
ou celui là encore :
- nationalité
- nationalitech
Les utilisateur de ma platform s’inscrivent et quelqu’un a un souhait (le champ objet) et selon qu’il souhait il remplit un ensemble de champ je m’excuse je peux pas trop parlé puisque j’ai pas le droit de parler à cet projet mais je vous donne un exemple j’ai un utilisateur qui cherche un emploi il inscrit avec un tel age et nationnalité … un autre utlisateur va inscrir pour déposer un offre d’emploi où il préfère un tel age (agech) w nationnalité(nationnalitéch)
concernant les - nom_emploi
- nom_emploid
- nom_emploing
- nom_emploit je peux l'éliminer
mais le problème j'ai encore d'autre champs à ajouter
concernant les - nom_emploi
- nom_emploid
- nom_emploing
- nom_emploit je peux l'éliminer
mais le problème j'ai encore d'autre champs à ajouter
niuxe a écrit :
Je pense que tes données ne sont pas du tout intègres. Je t'invite à parcourir cet article : forme normalisée sql
@Niuxe: Merci au passage pour cet article qui m'a aidé en partie à comprendre quelques problématiques de relation entre les tables. Il m'a été profitable en tant qu'introduction à la méthode Merise que j'ai du mal à appréhender.
J'ai déjà eu des tables avec 200000 enregistrements de 60 champs et ça n'a jamais été un problème, pour autant que les index soient bien placés et qu'on sache quelles recherches sont typiquement faites sur les données.
Par contre, comme niuxe te l'a déjà conseillé, évite les champs qui font doublon. C'est un cauchemar à tous les niveaux pour la gestion et les recherches. Les requêtes avec des or ou des union partout sont lentes.
Les champs "Sexe" et "Sexch" me font penser que ton site doit probablement être bilingue. Si c'est le cas, sache que le multilinguisme est avant tout une question d'interface; ça n'a pas à se répercuter sur la structure des données, au-delà éventuellement d'un champ indiquant dans quelle langue les informations ont été saisies.
Par contre, comme niuxe te l'a déjà conseillé, évite les champs qui font doublon. C'est un cauchemar à tous les niveaux pour la gestion et les recherches. Les requêtes avec des or ou des union partout sont lentes.
Les champs "Sexe" et "Sexch" me font penser que ton site doit probablement être bilingue. Si c'est le cas, sache que le multilinguisme est avant tout une question d'interface; ça n'a pas à se répercuter sur la structure des données, au-delà éventuellement d'un champ indiquant dans quelle langue les informations ont été saisies.
Merci QuentinC, j'ai passer toute la journal à essayer de travailler avec la bibliothèque Gettext mais en vain, alors je commence à traduire mais pages manuellement heureusement que j'ai pas beaucoup de contenue et concernant ma base de données je trouve que c'est mieux de d'ajouter autre table à chaque langue par exemple j'ai déja un table user j'ajoute un autre nommée user_eng et voilà c marche bien.
Pensez vous que je suis en bonne route merci.
Pensez vous que je suis en bonne route merci.
Olivier C a écrit :
@Niuxe: Merci au passage pour cet article qui m'a aidé en partie à comprendre quelques problématiques de relation entre les tables. Il m'a été profitable en tant qu'introduction à la méthode Merise que j'ai du mal à appréhender.
Ahh lalala, tu es tombé dans le panneau (un de plus). T'inquiète beaucoup font la même erreur. Là tu dois faire un gros :

SGBDR veut dire système de base de données relationnelle. Cette définition ne veut surtout pas dire une relation entre les tables ! La relation est entre les champs et la table et entre la ligne de données et la clef. C'est ce qui va déterminer l'unicité des données ! Ce qui est extrêmement important (l'importance de la clef. J'entends par là, pas de clef primaire composite !).
Je ne vais pas rentrer dans les détails. Je vais effleurer le sujet. Il y a énormément à dire et je ne connais pas tout.
 Lorsque Edgar Franck Codd créa le schéma des SGBDR (70's), il prit au départ conscience que l'ennemi d'une base de données, ce sont les doublons et la redondance (l'intégrité des données....). C'est ainsi qu'il créa le système d'index, clef primaire, secondaire, jointure, select, insert, update, delete, etc., etc., et le NULL.
Lorsque Edgar Franck Codd créa le schéma des SGBDR (70's), il prit au départ conscience que l'ennemi d'une base de données, ce sont les doublons et la redondance (l'intégrité des données....). C'est ainsi qu'il créa le système d'index, clef primaire, secondaire, jointure, select, insert, update, delete, etc., etc., et le NULL. Le NULL pendant longtemps fut montré du doigt, parce qu'il n'avait aucune utilité selon Chris Date. Or Codd voulait donner une valeur à quelque chose de non applicable ou inconnu. C'est à dire, si on stocke dans une base par exemple une nouvelle plante découverte en Amazonie, il y a de fortes chances que certaines données soient manquantes parce que la plante n'a pas encore été étudiée. Par contre, elle est répertoriée ! Codd voulait supprimer le NULL et le remplacer par inconnu et valeur non applicable. Il n'a jamais pu le faire.
Attention Codd n'a pas inventé le SQL. C'est pas lui. Codd et Date sont les papas des SGBDR (système de base de données relationnelles). Le SQL et le relationnelle, c'est pas tout à fait la même chose. D'ailleurs, il y a un bon exemple. PostgreSql était à l'origine basé sur le langage Quel. À l'époque ce langage était beaucoup plus performant que le SQL. Les travaux de Codd et Date s'appuyaient sur le langage SEQUEL (le papa du sql). Mais alors pourquoi le SQL s'est imposé dans le monde ? Parce que certains informaticiens de l'époque comme Bob Miner (le dev), Ed Oates (tete pensante) qui avait lu les specs de Codd et Date (l'unicité des données), Larry Ellison (tete pensante) qui avait repris les specs de Donald D. Chamberlin sur le SEQUEL, s'associèrent pour développer le SQL et en faire un langage plus élaboré. Ils créèrent une base de données relationnelle par la suite. Cette base de données s'appelle Oracle....
Attention, ça ne veut pas dire que Donald D. Chamberlin n'a pas travaillé sur le SQL. Les papas du SQL sont :
Donald D. Chamberlin
Raymond F. Boyce
Bob Miner
Ed Oates
Larry Ellison.
Modifié par niuxe (21 Jul 2015 - 01:45)
QuentinC a écrit :
J'ai déjà eu des tables avec 200000 enregistrements de 60 champs et ça n'a jamais été un problème, pour autant que les index soient bien placés et qu'on sache quelles recherches sont typiquement faites sur les données.
Par contre, comme niuxe te l'a déjà conseillé, évite les champs qui font doublon. C'est un cauchemar à tous les niveaux pour la gestion et les recherches. Les requêtes avec des or ou des union partout sont lentes.
+1
QuentinC a écrit :
Les champs "Sexe" et "Sexch" me font penser que ton site doit probablement être bilingue. Si c'est le cas, sache que le multilinguisme est avant tout une question d'interface; ça n'a pas à se répercuter sur la structure des données, au-delà éventuellement d'un champ indiquant dans quelle langue les informations ont été saisies.
Au contraire. Un mauvaise modélisation de ta sgbdr peut entrainer des conséquences regrettables. Le plus difficile est de modéliser. En général, lorsque je dois faire du multilingues, je vais créer une table langues. Ensuite, je crées dans mes autres tables des clefs étrangères qui pointent vers les id de la table langues.
salut,
si la méthode UML est plus "moderne", personnellement, je trouve MERISE bien plus logique et structurée. Si tu te bases sur la méthode MERISE, sache que cette table unique que tu présente peut se diviser en au moins trois tables distinctes.Si tu mets plusieurs champs portant le nom "emploi", autant crée une table "Emplois" et porter dedans les infos nécessaires.
Sans vouloir chipoter, les champs dans le genre "tel" devraient aussi être mis dans une table à part (si tu veux évoluer plus tard vers différents types de tel mobile/bureau/maison...).
Comme déjà dit, le plus important dans la conception d'une BDD c'est sa modélisation.
si la méthode UML est plus "moderne", personnellement, je trouve MERISE bien plus logique et structurée. Si tu te bases sur la méthode MERISE, sache que cette table unique que tu présente peut se diviser en au moins trois tables distinctes.Si tu mets plusieurs champs portant le nom "emploi", autant crée une table "Emplois" et porter dedans les infos nécessaires.
Sans vouloir chipoter, les champs dans le genre "tel" devraient aussi être mis dans une table à part (si tu veux évoluer plus tard vers différents types de tel mobile/bureau/maison...).
Comme déjà dit, le plus important dans la conception d'une BDD c'est sa modélisation.
Bonjour,Zelalsan vous avez bien compris ce que je veux et votre proposition de créer un table emploi à part est trés logique donc finalement je dois resortir qlq champs en des tables (dont la relation 1,*) comme le champ objet puisque un utilisateur peut avoir un ou plusieurs objet et je dois également ajouter un table langue(id_langue,nom_langue) et je met id_langue comme clé étrangère dans t mes tables et concernant la traduction j’utilise la bibliothèque gettext avec le logiciel Poedit
Zelalsan a écrit :
si la méthode UML est plus "moderne", personnellement, je trouve MERISE bien plus logique et structurée.
Dire que l'uml n'est pas assez structuré, c'est un peu pousser mémé dans les orties.

En fait je comprends ce que tu veux dire. Avec l'UML, on peut tout modéliser. Je dis bien tout ! On peut modéliser une partie de foot, une partie de flipper, des voitures à un carrefour où il y a un feu de signalisation (ça rappelle des souvenirs....), une jungle où il y a un lion, une antilope, un ruisseau, etc.
Avec Merise, ça se cantonne à modéliser un système d'information.