Bonjour à tous
Voici un autre schéma de données
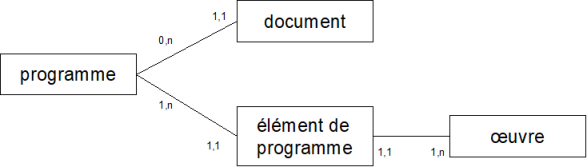
Il s'agit d'un programme de travail du chœur
De façon très simplifiée un "programme" a d'une part un nombre quelconque de "documents" attachés et un certain nombre d'"œuvres" qui le constituent.
"documents" et "œuvres" sont des objets qui n'ont en commun que le fait d'être rattachés au même programme.
En mode database, j'ai fait
- la table des programmes
- la table des œuvres
- la table des "éléments de programme" qui permet de rattacher une œuvre à un programme, sachant que la même œuvre peut se retrouver dans des programmes différents, voire plusieurs fois dans le même programme
- la table des "documents de programme" qui permet de rattacher une à un programme un document défini par son URL
Le problème c'est quand je voudrais en UNE SEULE requête obtenir tous les éléments d'un programme.
Ce que je voudrais obtenir et que ma connaissance fragmentaire du SQL ne me permet pas c'est une suite de lignes contenant les infos des documents suivi d'une suite de lignes contenant les infos des œuvres. Une œuvre ayant souvent plusieurs fichiers attachés (partition, différents enregistrements, traduction du texte, etc.) il y a plusieurs lignes par œuvre.
Pourriez vous me dire comment faire?
Merci de votre aide.
Modifié par PapyJP (28 Jun 2020 - 10:30)
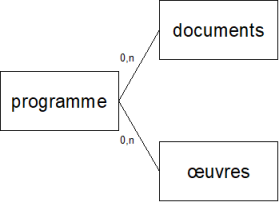
Voici un autre schéma de données
Il s'agit d'un programme de travail du chœur
De façon très simplifiée un "programme" a d'une part un nombre quelconque de "documents" attachés et un certain nombre d'"œuvres" qui le constituent.
"documents" et "œuvres" sont des objets qui n'ont en commun que le fait d'être rattachés au même programme.
En mode database, j'ai fait
- la table des programmes
- la table des œuvres
- la table des "éléments de programme" qui permet de rattacher une œuvre à un programme, sachant que la même œuvre peut se retrouver dans des programmes différents, voire plusieurs fois dans le même programme
- la table des "documents de programme" qui permet de rattacher une à un programme un document défini par son URL
Le problème c'est quand je voudrais en UNE SEULE requête obtenir tous les éléments d'un programme.
Ce que je voudrais obtenir et que ma connaissance fragmentaire du SQL ne me permet pas c'est une suite de lignes contenant les infos des documents suivi d'une suite de lignes contenant les infos des œuvres. Une œuvre ayant souvent plusieurs fichiers attachés (partition, différents enregistrements, traduction du texte, etc.) il y a plusieurs lignes par œuvre.
Pourriez vous me dire comment faire?
Merci de votre aide.
Modifié par PapyJP (28 Jun 2020 - 10:30)